
كيف تعمل نماذج اللغة الكبيرة (LLMs) بالضبط؟ م/7
كيف يفهم ChatGPT سؤالك ويُجيب عليه؟ شرح بسيط ومُصوَّر لآلية عمل نماذج اللغة الكبيرة من الكلمة الأولى حتى الرد الأخير.

كيف تعمل نماذج اللغة الكبيرة (LLMs) بالضبط؟
السلسلة: الذكاء الاصطناعي من الصفر إلى الاحتراف | المقالة: السابعة من ستين الموقع: efhm.online | المستوى: مبتدئ | وقت القراءة: 10 دقائق
مقدمة: ما الذي يحدث بالضبط حين تكتب سؤالاً؟
حين تكتب لـ ChatGPT “اشرح لي ما هي الثقوب السوداء بأسلوب بسيط”، يحدث داخل الخوادم شيء مذهل في أجزاء من الثانية: نصك يتحول إلى أرقام، تمر عبر مئات الطبقات الحسابية، تُحلَّل العلاقات بين كلماتك، ثم تخرج في النهاية كلمة كلمة إجابة سلسة وطبيعية.
هذه العملية كلها تجريها نماذج اللغة الكبيرة — أو LLMs اختصاراً لـ Large Language Models. في هذه المقالة ستفهم هذه العملية فهماً حقيقياً، بدون رياضيات ولا تعقيد.
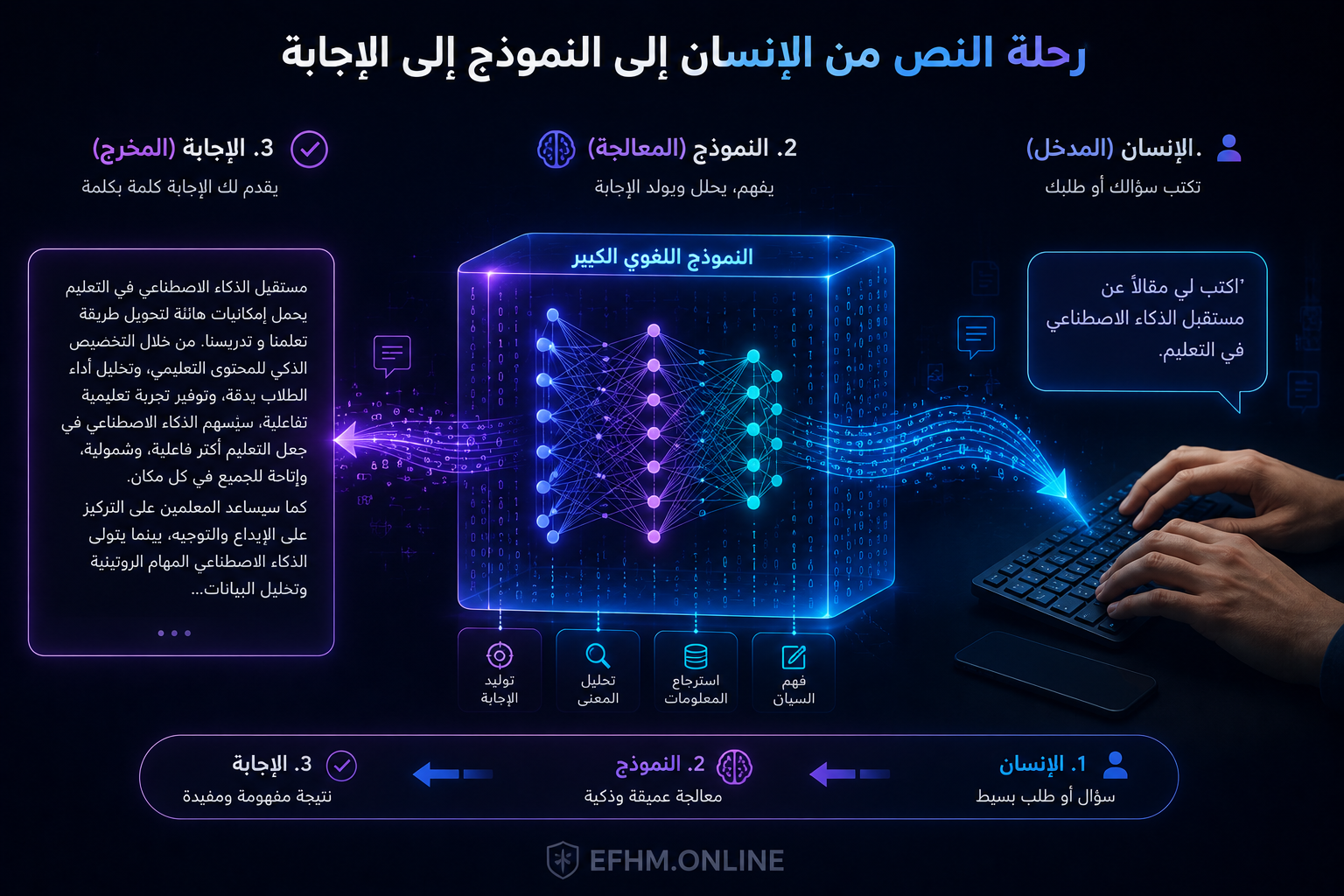
ما هو نموذج اللغة الكبير (LLM)؟
نموذج اللغة الكبير هو برنامج ضخم تدرّب على كميات هائلة من النصوص — كتب ومقالات وصفحات إنترنت ومحادثات — حتى أصبح قادراً على فهم اللغة البشرية والرد عليها بطريقة طبيعية.
كلمة “كبير” هنا لا تعني حجم البرنامج على الشاشة، بل تعني حجم النموذج الرياضي بداخله: مليارات أو تريليونات من المعاملات الرياضية (Weights) التي تُمثل “معرفته” المخزّنة.
أشهر الأمثلة: GPT-4 من OpenAI، وGemini Ultra من Google، وClaude 3 من Anthropic.
الفكرة الجوهرية: التنبؤ بالكلمة التالية
رغم كل هذا التعقيد، يقوم كل نموذج لغة في جوهره على مبدأ بسيط واحد:
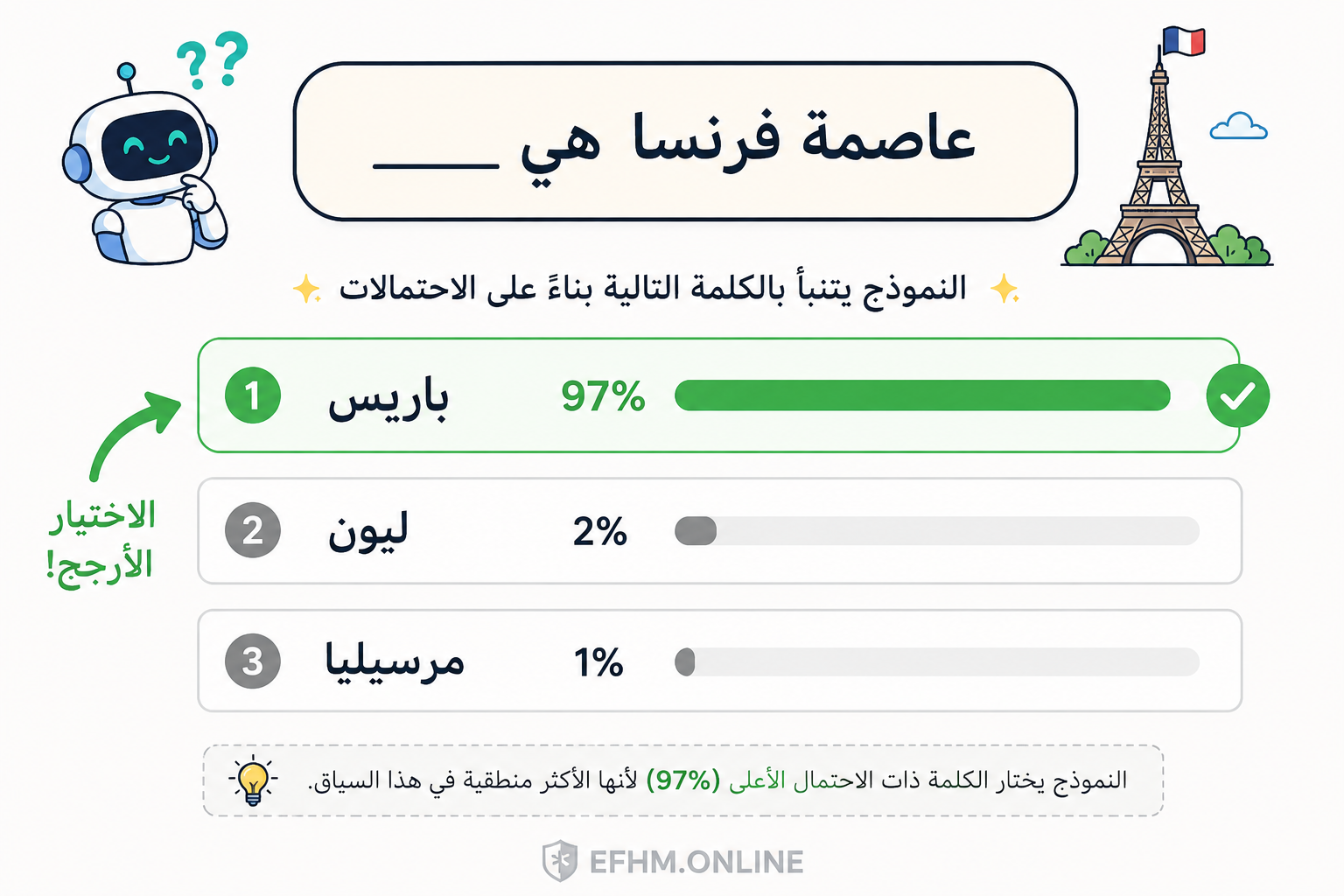
يتنبأ بالكلمة الأرجح أن تأتي بعد الكلمات السابقة.
حين تكتب “عاصمة فرنسا هي…”، يعرف النموذج أن الكلمة التالية الأرجح هي “باريس” لأنه رأى هذه الجملة أو ما يشبهها ملايين المرات في بيانات التدريب.
لكن “التنبؤ بالكلمة التالية” وحده لا يُفسر كيف يكتب النموذج فقرات متماسكة ويُجيب على أسئلة معقدة — هنا يكمن العمق الحقيقي.
المرحلة الأولى: Tokenization — تقطيع النص إلى قطع
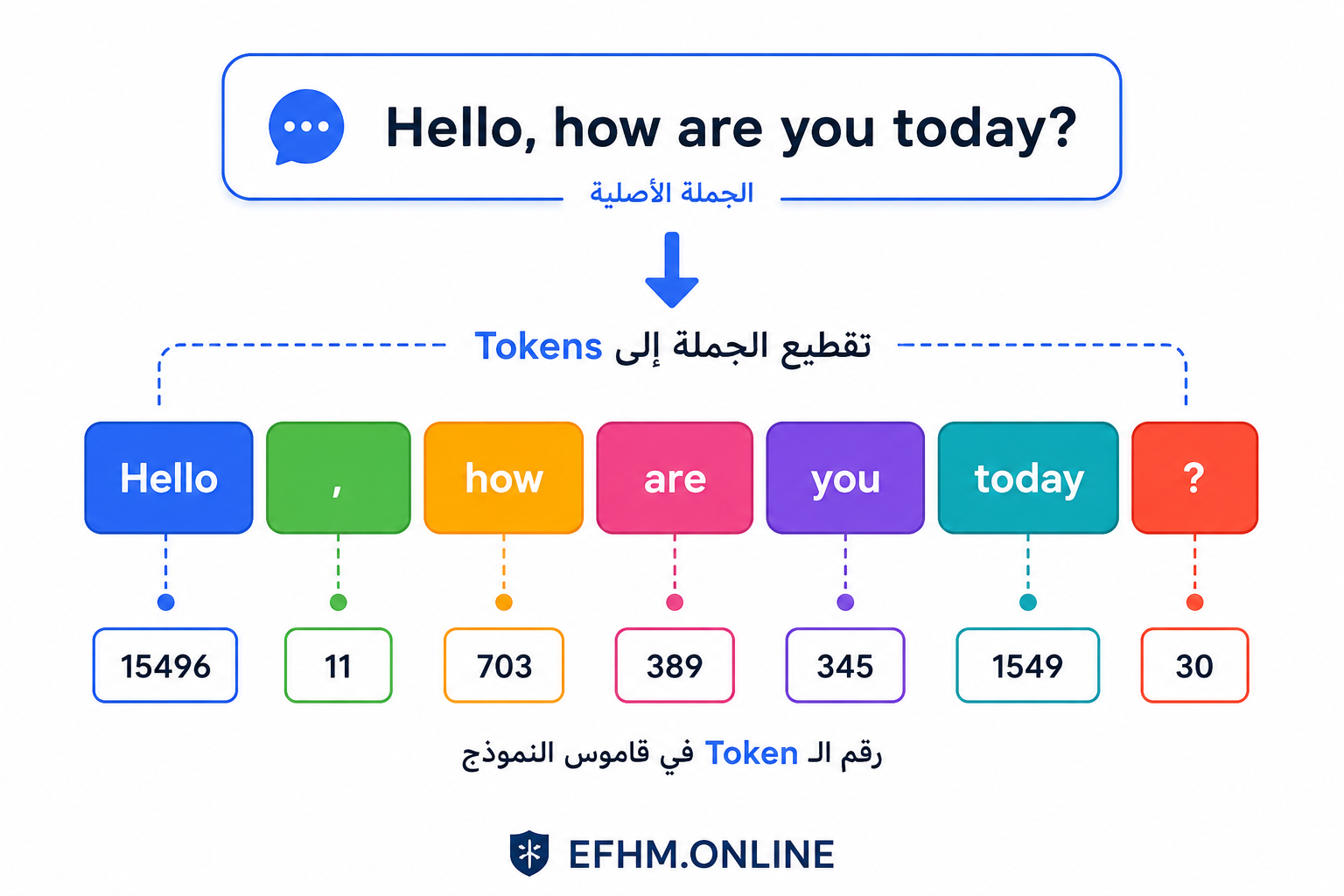
أول شيء يفعله النموذج حين يستقبل نصّك هو تقطيعه إلى وحدات صغيرة تُسمى Tokens (رموز أو وحدات لغوية).
ما هو الـ Token بالضبط؟
الـ Token ليس دائماً كلمة كاملة. قد يكون:
- كلمة كاملة: “مصر” = Token واحد
- جزءاً من كلمة: “الاصطناعي” = عدة Tokens
- علامة ترقيم: “؟” = Token واحد
- مقطعاً إنجليزياً: “artificial” = يُقسَّم إلى “artif” + “icial”
لماذا يُقسَّم النص هكذا؟
لأن الحاسوب لا يفهم الكلمات — يفهم فقط الأرقام. التقطيع إلى Tokens هو الخطوة الأولى لتحويل اللغة البشرية إلى أرقام يمكن معالجتها.
مثال عملي: الجملة: “ما عاصمة مصر؟” بعد التقطيع: [“ما”, ” عاصمة”, ” مصر”, “؟”] كل Token سيُحوَّل لاحقاً إلى رقم فريد في قاموس النموذج.
المرحلة الثانية: Embedding — الأرقام التي تحمل المعنى
بعد تحويل الكلمات إلى أرقام بسيطة، تأتي مرحلة أعمق تُسمى Embedding (التضمين).
الفكرة الجوهرية
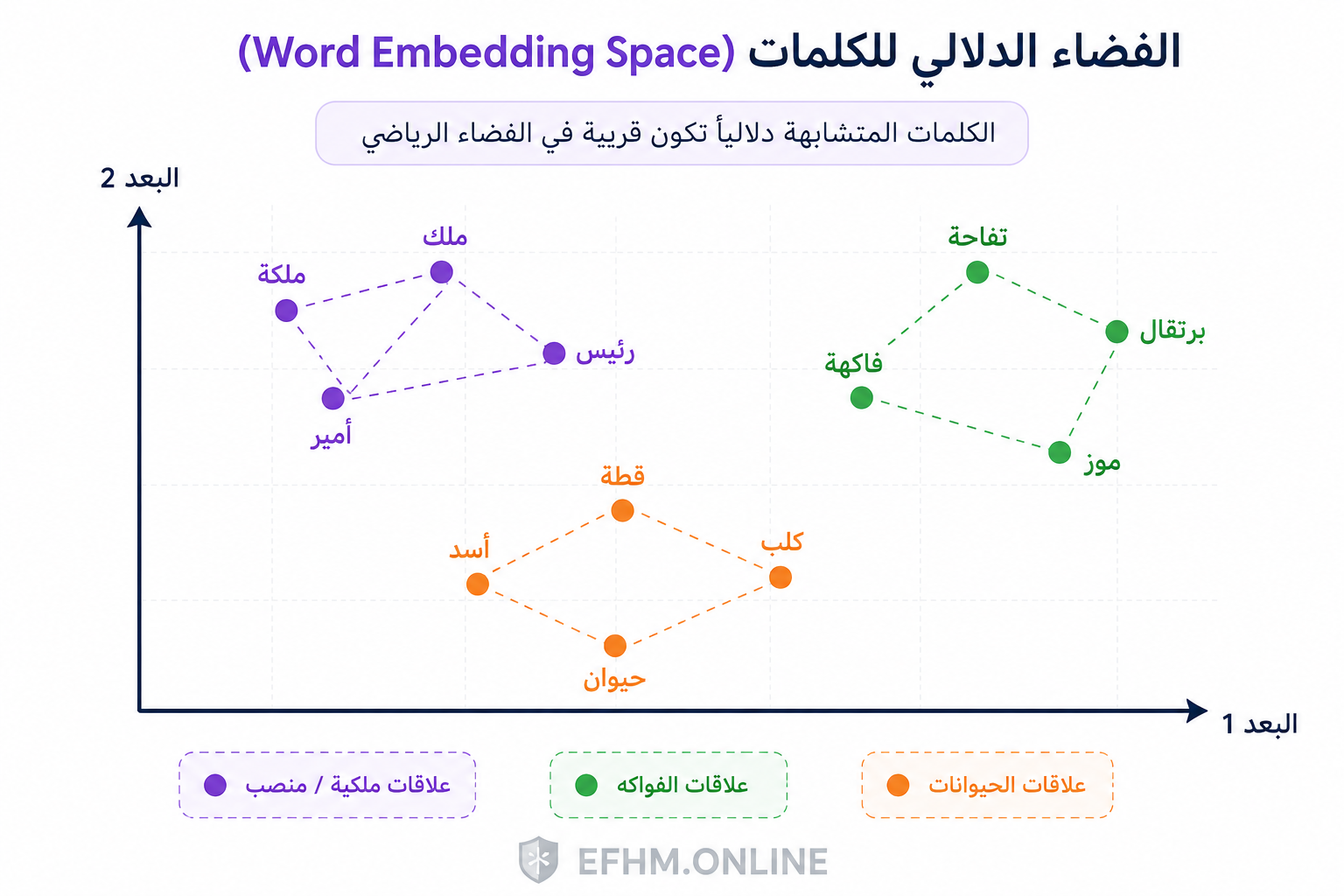
كل Token يُحوَّل إلى متجه رياضي — قائمة طويلة من الأرقام قد تصل إلى آلاف الأبعاد — تُمثّل معنى الكلمة وعلاقاتها بالكلمات الأخرى في الفضاء الرياضي.
تشبيه يُوضح الفكرة
تخيل خريطة جغرافية: باريس وليون قريبتان لأنهما في فرنسا. لكن باريس وطوكيو بعيدتان.
الـ Embedding يفعل نفس الشيء للكلمات: “ملك” و”ملكة” قريبتان في الفضاء الرياضي لأنهما مرتبطتان بالحكم. “ملك” و”تفاحة” بعيدتان جداً.
هذه القرب والبعد بين الكلمات هو ما يُمكّن النموذج من فهم السياق والعلاقات بين المفاهيم — حتى حين لم يرَ الجملة بعينها من قبل.
المرحلة الثالثة: Transformer — قلب النموذج النابض
هنا تكمن الثورة الحقيقية. في عام 2017، نشر باحثون في Google ورقة بحثية بعنوان “Attention Is All You Need” قلبت عالم الذكاء الاصطناعي. اخترعوا فيها بنية جديدة تُسمى Transformer.
ما الذي يجعل Transformer مختلفاً؟
قبل Transformer، كانت النماذج تقرأ النص كلمة كلمة بالترتيب — مثل قراءة كتاب سطراً بسطر لا يمكنك تجاوزه. هذا جعلها بطيئة وعاجزة عن استيعاب النصوص الطويلة.
Transformer اخترع آلية الانتباه (Attention Mechanism) التي تُتيح للنموذج النظر إلى جميع الكلمات في الجملة في آنٍ واحد وتحديد أيها أكثر أهمية للكلمة الحالية.
مثال عملي على آلية الانتباه
الجملة: “ذهبت سارة إلى السوق وهي كانت سعيدة”
حين يُحاول النموذج فهم معنى “هي”، تنظر آلية الانتباه إلى كل الكلمات السابقة وتُحدد أن “سارة” هي المرجع الأكثر احتمالاً — لأن “سارة” أقرب اسم مؤنث في الجملة.
هذا ما يُسمى بـفهم الإحالة — قدرة النموذج على تتبع ضمائر وعلاقات عبر جملة طويلة.
الطبقات المتعددة — عمق الفهم
نموذج مثل GPT-4 يحتوي على 96 طبقة Transformer مُكدَّسة فوق بعضها. كل طبقة تُضيف مستوى أعمق من الفهم:
الطبقات الأولى تفهم التركيب النحوي البسيط: هذه جملة اسمية، هذا فعل.
الطبقات الوسطى تفهم المعنى والسياق: هذه جملة سؤال عن مكان جغرافي.
الطبقات العميقة تفهم النية والأسلوب: هذا شخص يريد إجابة مباشرة بدون تفاصيل زائدة.

المرحلة الرابعة: الإخراج — كلمة كلمة حتى تكتمل الإجابة
بعد مرور النص عبر طبقات Transformer، يصل النموذج إلى المرحلة الأخيرة: توليد الإجابة.
كيف تُكتب الإجابة كلمة كلمة؟
النموذج لا يُنتج الإجابة كلها دفعة واحدة. بل يفعل ما يلي:
الخطوة الأولى: يُحلل النص الكامل (سؤالك + أي سياق سابق) ويتنبأ بالكلمة الأولى في الإجابة.
الخطوة الثانية: يُضيف الكلمة الأولى إلى النص ثم يُعيد الحساب ليتنبأ بالكلمة الثانية.
الخطوة الثالثة: يستمر هكذا كلمة كلمة حتى يصل إلى نقطة نهاية طبيعية.
هذه العملية التكرارية هي التي تُعطي ChatGPT تلك الطريقة المميزة في الكتابة — كأنه يُفكر ويكتب في الوقت الفعلي.
لماذا أحياناً تختلف الإجابات على نفس السؤال؟
لأن النموذج لا يختار دائماً الكلمة الأعلى احتمالاً. يُضيف قدراً من العشوائية المحسوبة يُسمى درجة الحرارة (Temperature). درجة حرارة عالية = ردود أكثر إبداعاً وتنوعاً. درجة حرارة منخفضة = ردود أكثر تنبؤية وثباتاً.

ملخص الرحلة الكاملة
لنُلخّص رحلة جملتك داخل نموذج اللغة في خطوات واضحة:
| المرحلة | ما يحدث | المثال |
|---|---|---|
| Tokenization | تقطيع النص إلى وحدات | “مصر” → [Token رقم 4521] |
| Embedding | تحويل كل Token إلى متجه رياضي | [0.2, 0.8, 0.1, 0.6…] |
| Transformer | فهم السياق والعلاقات عبر 96 طبقة | “مصر” + “عاصمة” → يُدرك أنها سؤال جغرافي |
| الإخراج | توليد الإجابة كلمة كلمة | “القاهرة” ← احتمال 98% |
ماذا يعني هذا لك عملياً؟
فهم آلية عمل LLMs يُعطيك مزايا حقيقية في استخدامك اليومي:
أولاً: ستفهم لماذا السياق مهم جداً. النموذج يفهم كل رسالة في سياق المحادثة كلها. كلما أعطيته سياقاً أوضح، كانت إجابته أدق.
ثانياً: ستفهم حدود “الذاكرة”. النموذج لا يتذكر ما قبل المحادثة الحالية (إلا بميزات خاصة). نافذة السياق المحدودة تعني أنه في المحادثات الطويلة جداً قد “ينسى” ما قيل في البداية.
ثالثاً: ستتعامل مع الهلوسة بذكاء. النموذج مُصمَّم للتنبؤ بما “يبدو صحيحاً” لغوياً، لا للتحقق من صحة المعلومات. لذا يبدو واثقاً حتى حين يُخطئ. دائماً تحقق من المعلومات الحساسة.
رابعاً: ستكتب أوامر (Prompts) أفضل. ستعرف أن النموذج يفهم الكلمات بسياقها ودلالاتها، لا بمعناها الحرفي فقط. كلما كانت أوامرك أوضح وأكثر سياقاً، كانت الإجابات أجود.
خلاصة المقالة
نماذج اللغة الكبيرة تعمل في أربع مراحل: تُقطّع نصك إلى Tokens، تُحوّلها إلى متجهات رياضية تحمل المعنى، تُمررها عبر طبقات Transformer التي تفهم السياق والعلاقات، ثم تُولّد الإجابة كلمة كلمة بناءً على الاحتمالية. الفهم الجوهري لهذه الآلية يجعلك مستخدماً أذكى وأكثر فاعلية.
المقالة القادمة
في المقالة الثامنة، سننتقل من فهم الذكاء الاصطناعي إلى استخدامه باحتراف. سنشرح الذكاء الاصطناعي التوليدي — ما الذي يستطيع إنشاؤه من نصوص وصور وصوت وفيديو — وكيف أصبح هذا النوع من الذكاء الاصطناعي أداة إبداعية في يد كل إنسان.
الذكاء الاصطناعي التوليدي — ماذا يستطيع أن يصنع؟ م/8
نهاية المقالة السابعة — سلسلة الذكاء الاصطناعي من الصفر إلى الاحتراف efhm.online
