
كيف يتعلم الذكاء الاصطناعي؟ — شرح بسيط بلا تعقيد م/4
كيف تحوّلت ملايين الصفحات على الإنترنت إلى نموذج يفهمك ويُجيبك؟ شرح بسيط ومُصوَّر لآلية تعلم الذكاء الاصطناعي بدون رياضيات ولا تعقيد.

كيف يتعلم الذكاء الاصطناعي؟ — شرح بسيط بلا تعقيد
السلسلة: الذكاء الاصطناعي من الصفر إلى الاحتراف | المقالة: الرابعة من ستين الموقع: efhm.online | المستوى: مبتدئ | وقت القراءة: 10 دقائق
مقدمة: الطفل والنموذج
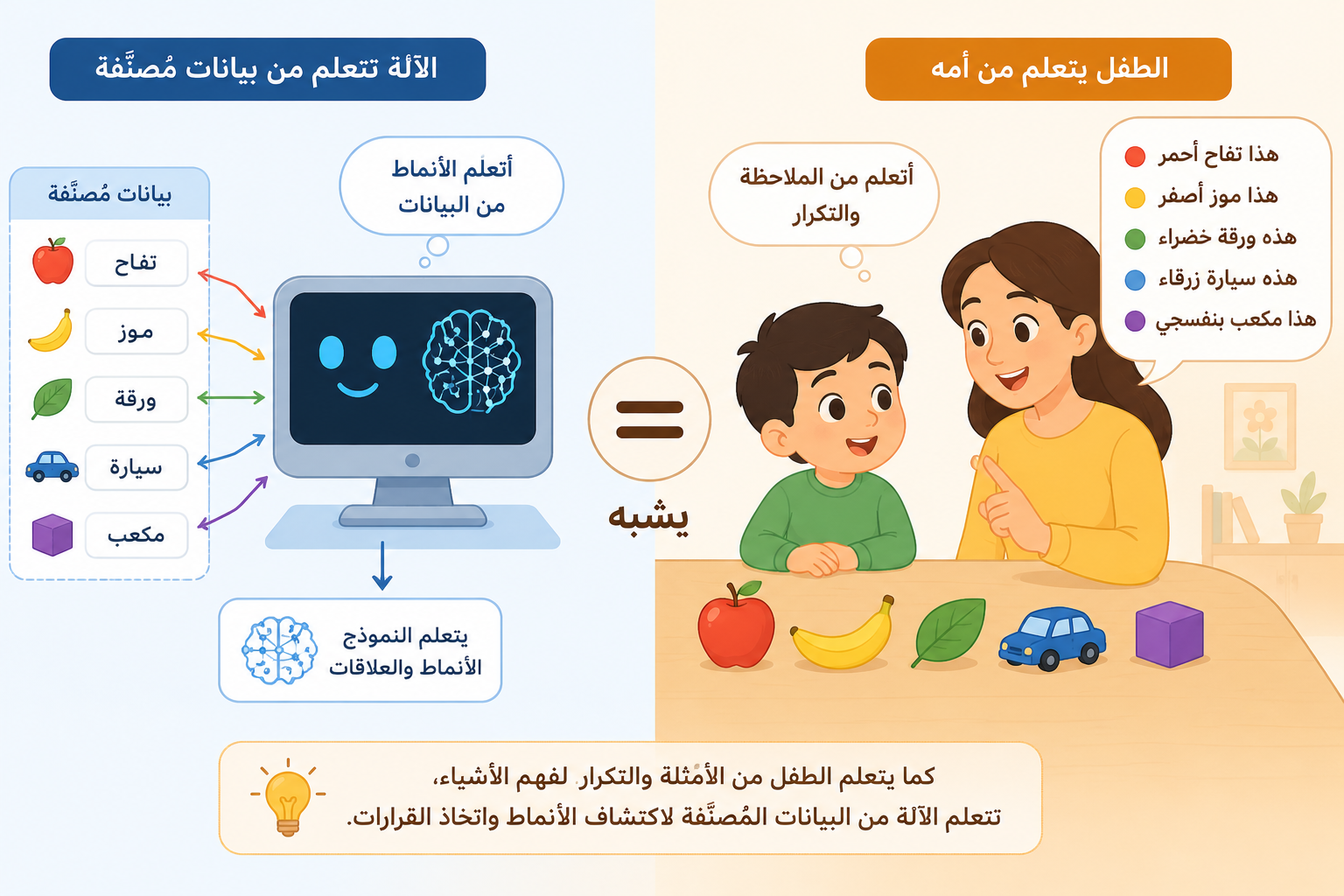
تخيل طفلاً في الثالثة من عمره يتعلم الألوان. تُريه أمه تفاحة حمراء وتقول “أحمر”. ثم سيارة حمراء وتقول “أحمر”. ثم قميصاً أزرق وتقول “أزرق”. بعد مئات هذه الأمثلة، يستطيع الطفل أن يتعرف على اللون الأحمر حتى في أشياء لم يرها من قبل.
الذكاء الاصطناعي يتعلم بطريقة مشابهة تماماً، مع فارق جوهري واحد: بينما يحتاج الطفل إلى مئات الأمثلة، يحتاج الذكاء الاصطناعي إلى مليارات منها — لكنه يُنهيها في أيام لا سنوات.
في هذه المقالة ستفهم بالضبط كيف تتحول كميات هائلة من البيانات إلى نموذج ذكي يتحدث معك ويُجيب على أسئلتك.
الخطوة الأولى: جمع البيانات — وقود التعلم
قبل أن يتعلم الذكاء الاصطناعي أي شيء، يحتاج إلى بيانات — وبكميات ضخمة جداً.
فكيف حصلت شركة OpenAI على البيانات التي دربت عليها ChatGPT؟ ببساطة: جمعت النص من الإنترنت. مقالات ويكيبيديا، كتب رقمية مفتوحة المصدر، منتديات، مواقع أخبار، منشورات علمية — مئات المليارات من الكلمات بعشرات اللغات.
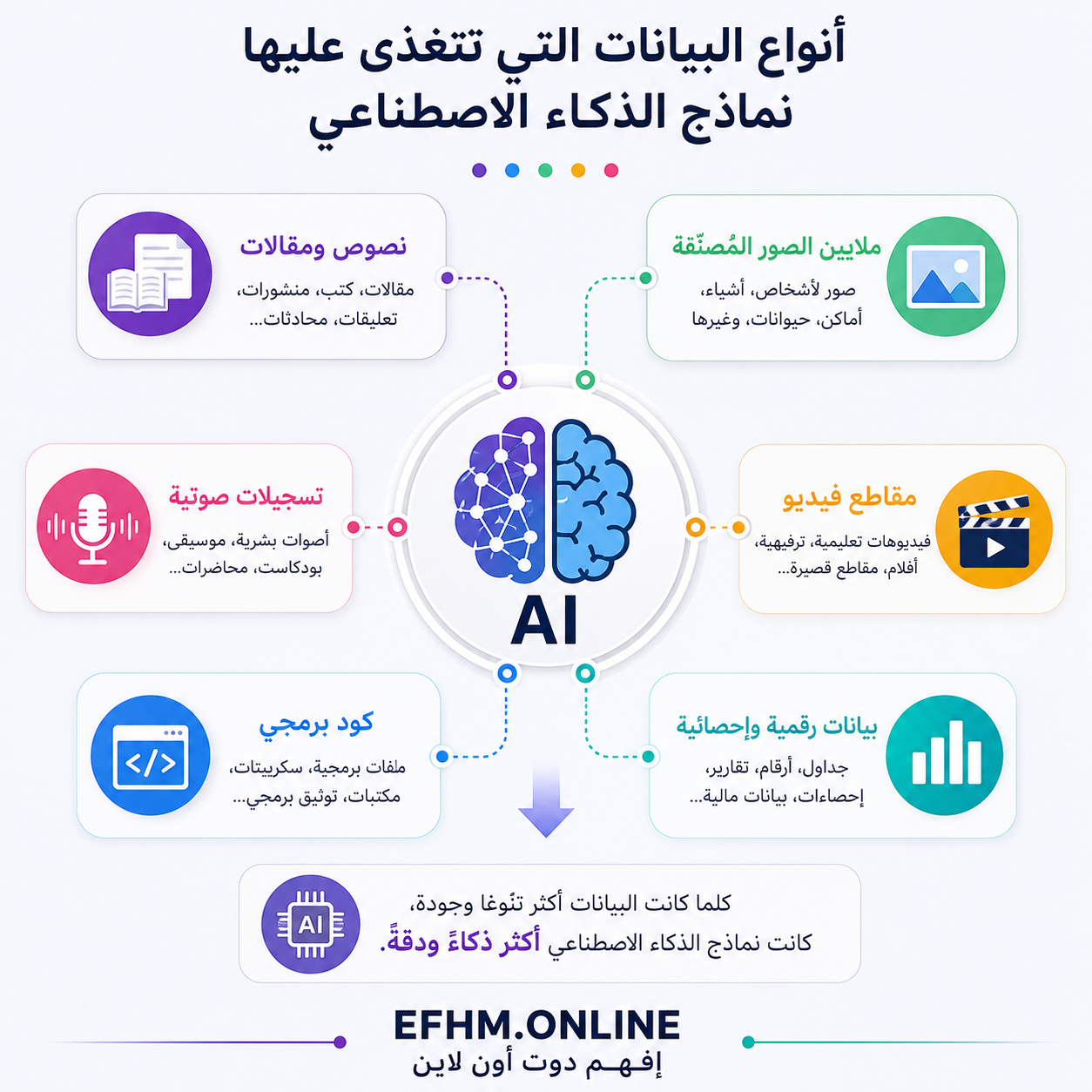
ما أنواع البيانات التي يتعلم منها الذكاء الاصطناعي؟
تختلف أنواع البيانات بحسب نوع النموذج الذي تريد بناءه:
نماذج اللغة (مثل ChatGPT): تتدرب على نصوص — مقالات وكتب ومحادثات وكود برمجي.
نماذج التعرف على الصور: تتدرب على ملايين الصور المُصنَّفة — “هذه قطة”، “هذا كلب”، “هذه سيارة”.
نماذج الصوت (مثل Whisper): تتدرب على ساعات طويلة من التسجيلات الصوتية مع نصوصها المقابلة.
نماذج الفيديو: تتدرب على ملايين مقاطع الفيديو مع أوصافها.
لماذا البيانات مهمة جداً؟
إليك قاعدة ذهبية في عالم الذكاء الاصطناعي:
النموذج لا يمكن أن يكون أذكى من البيانات التي تعلّم منها.
إذا تدربت على بيانات منحازة أو ناقصة أو مغلوطة، ستكون إجاباته منحازة وناقصة ومغلوطة. هذا هو السبب الذي يجعل جودة البيانات أهم في كثير من الأحيان من تصميم الخوارزمية نفسها.
الخطوة الثانية: التدريب — حين تتحول البيانات إلى معرفة
بعد جمع البيانات، تبدأ المرحلة الأصعب والأطول: التدريب.
كيف يعمل التدريب؟ — تشبيه الامتحانات
تخيل أنك تُحضِّر طالباً لامتحان كبير. تُعطيه ألف سؤال مع إجاباتها الصحيحة. يحل الطالب السؤال، تقارن إجابته بالإجابة الصحيحة، وتُخبره بالفرق. يُصحح مساره ويحاول مجدداً. بعد آلاف التكرارات، يبدأ في تقديم إجابات جيدة حتى على أسئلة لم يرها من قبل.
التدريب في الذكاء الاصطناعي يعمل بهذه الطريقة بالضبط، لكن بدلاً من طالب لديك ملايين الأوزان الرياضية داخل الشبكة العصبية، وبدلاً من آلاف الأسئلة لديك مليارات الأمثلة، وبدلاً من معلم يُصحح لديك خوارزمية تقيس الخطأ وتُعدّل الأوزان.
الخطأ والتصحيح — قلب عملية التعلم
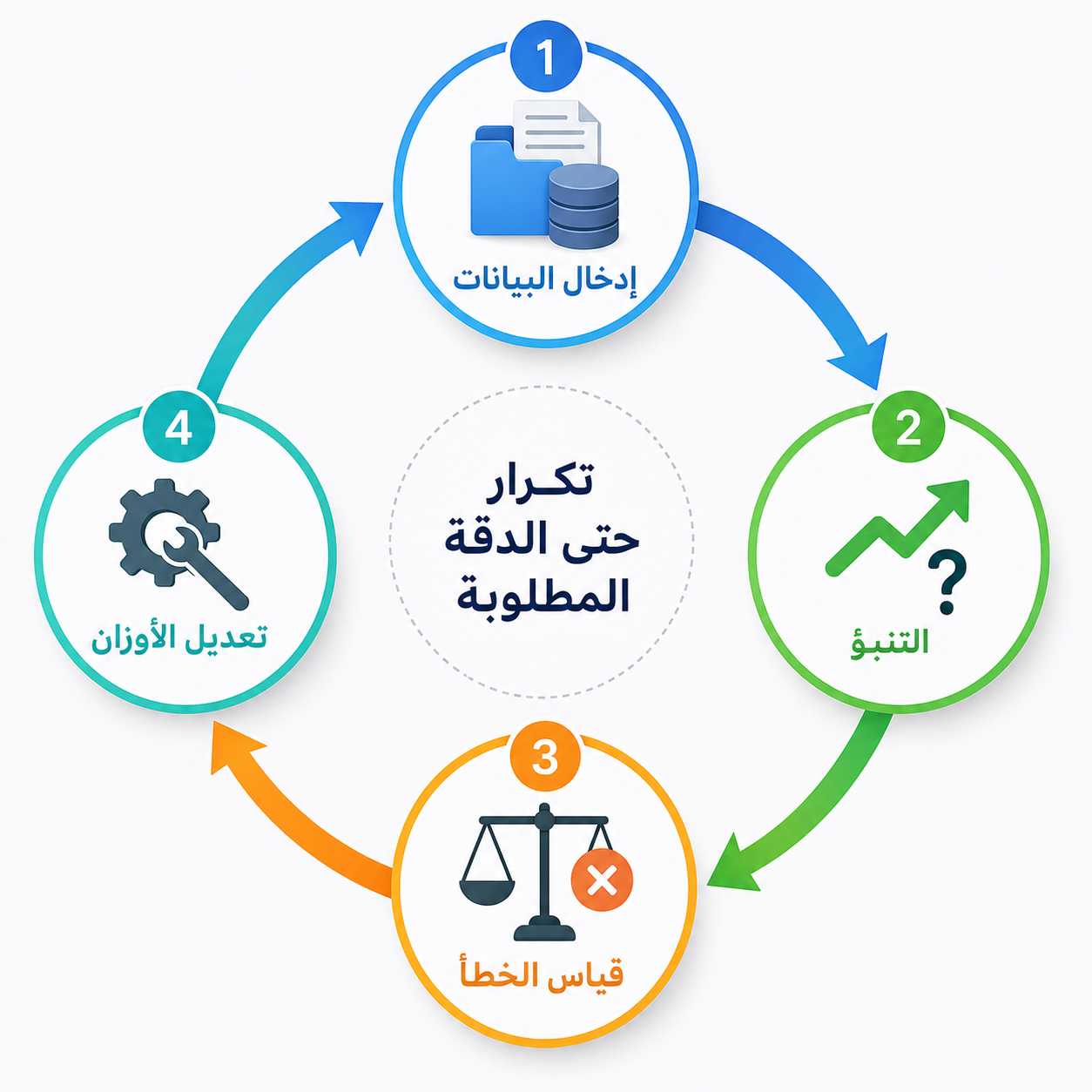
في كل جولة تدريب (تُسمى Epoch)، تمر البيانات كلها عبر الشبكة وتحدث ثلاثة أشياء:
أولاً — التنبؤ: تُعطى الشبكة مدخلاً (جملة ناقصة مثلاً) وتتنبأ بالكلمة التالية.
ثانياً — قياس الخطأ: تُقارَن التنبؤات بالإجابات الصحيحة المعروفة وتُحسب درجة الخطأ. هذا ما يُسمى بـ دالة الخسارة (Loss Function).
ثالثاً — التصحيح: تُعدَّل أوزان الشبكة بشكل آلي لتقليل الخطأ في الجولة القادمة. هذه العملية تُسمى الانتشار العكسي (Backpropagation).
تُكرَّر هذه الدورة الثلاثية ملايين المرات حتى يصل الخطأ إلى أدنى مستوياته.
الخطوة الثالثة: النموذج المدرَّب — ماذا يحدث بداخله؟
بعد انتهاء التدريب، يكون الناتج ما يُسمى بـ النموذج (Model). لكن ما هو النموذج في حقيقته؟
الأوزان — ذاكرة النموذج
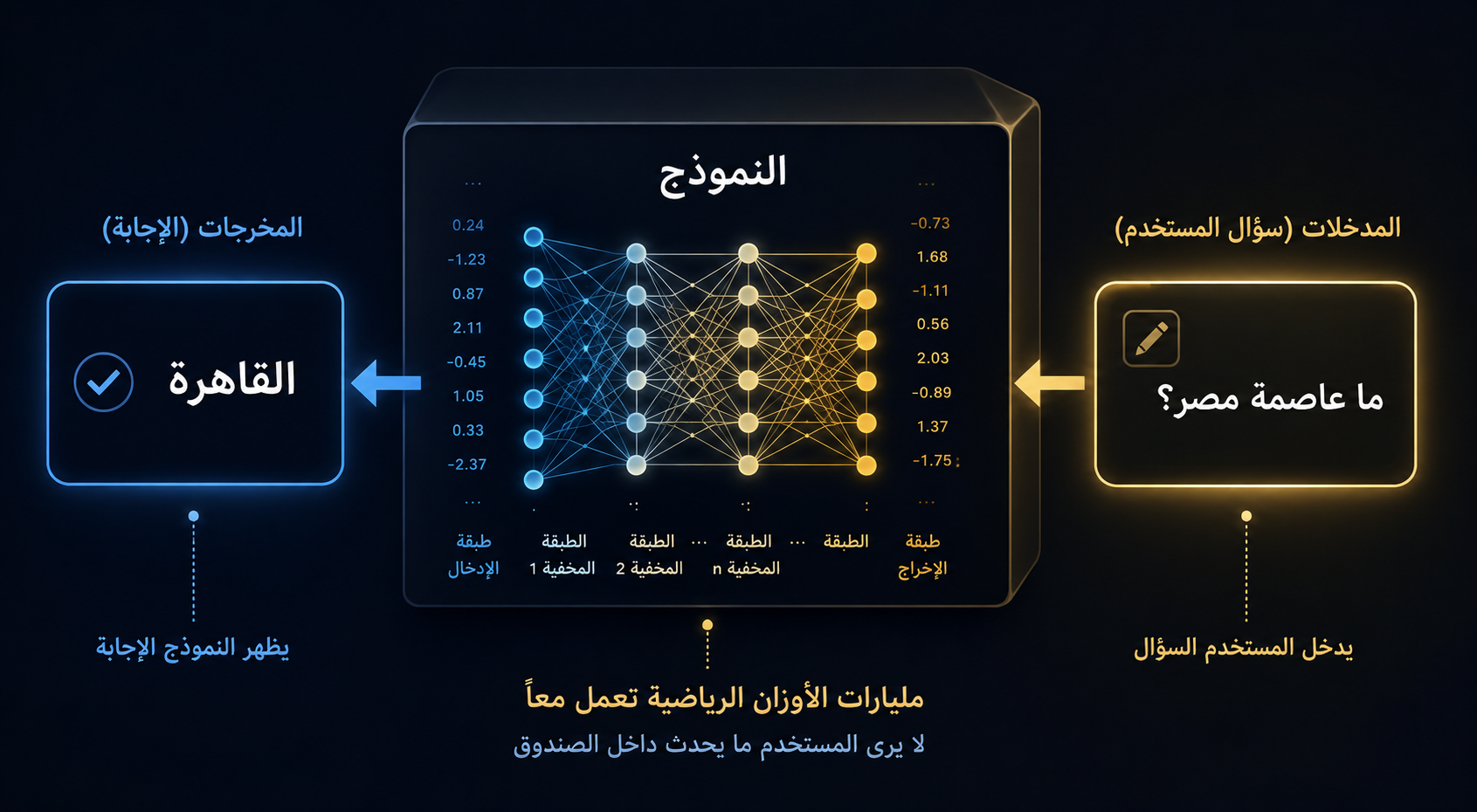
النموذج في جوهره هو مجموعة ضخمة من الأرقام تُسمى الأوزان (Weights). كل وزن يمثل درجة الارتباط بين فكرتين أو مفهومين. مجموع هذه الأوزان هو ما يمثل “معرفة” النموذج.
نموذج مثل GPT-4 يحتوي على ما يُقدَّر بـ تريليون وزن رياضي — رقم يصعب تخيله. هذه الأرقام هي التي تُحدد كيف يستجيب النموذج لأي سؤال تطرحه.
كيف يُجيب النموذج على سؤالك؟
حين تكتب لـ ChatGPT “ما عاصمة مصر؟”، تحدث هذه الأشياء في أجزاء من الثانية:
تُحوَّل جملتك إلى أرقام (هذه العملية تُسمى Tokenization)، تمر هذه الأرقام عبر مئات الطبقات من الشبكة العصبية، كل طبقة تُعدّل وتُصفّي المعلومات، وفي النهاية تظهر الأرقام التي تُترجم إلى الكلمة “القاهرة”.
كل هذا يحدث في أقل من ثانية واحدة.
الخطوة الرابعة: التقييم والضبط الدقيق
بعد انتهاء التدريب الأساسي، لا يُطلق النموذج للعموم فوراً. تمر عليه مرحلة حاسمة تُسمى الضبط الدقيق (Fine-tuning).
لماذا يحتاج النموذج إلى ضبط دقيق؟
النموذج في مرحلة التدريب الأولى يتعلم “التنبؤ بالكلمة التالية” — وهذا يجعله يُنتج نصاً منطقياً، لكنه قد لا يكون مفيداً أو آمناً كمساعد.
تخيل أن شخصاً قرأ ملايين الكتب لكنه لم يُحسن التحدث مع الآخرين بعد — هو مثقف لكن يحتاج إلى تدريب اجتماعي. هذا ما يفعله الضبط الدقيق.
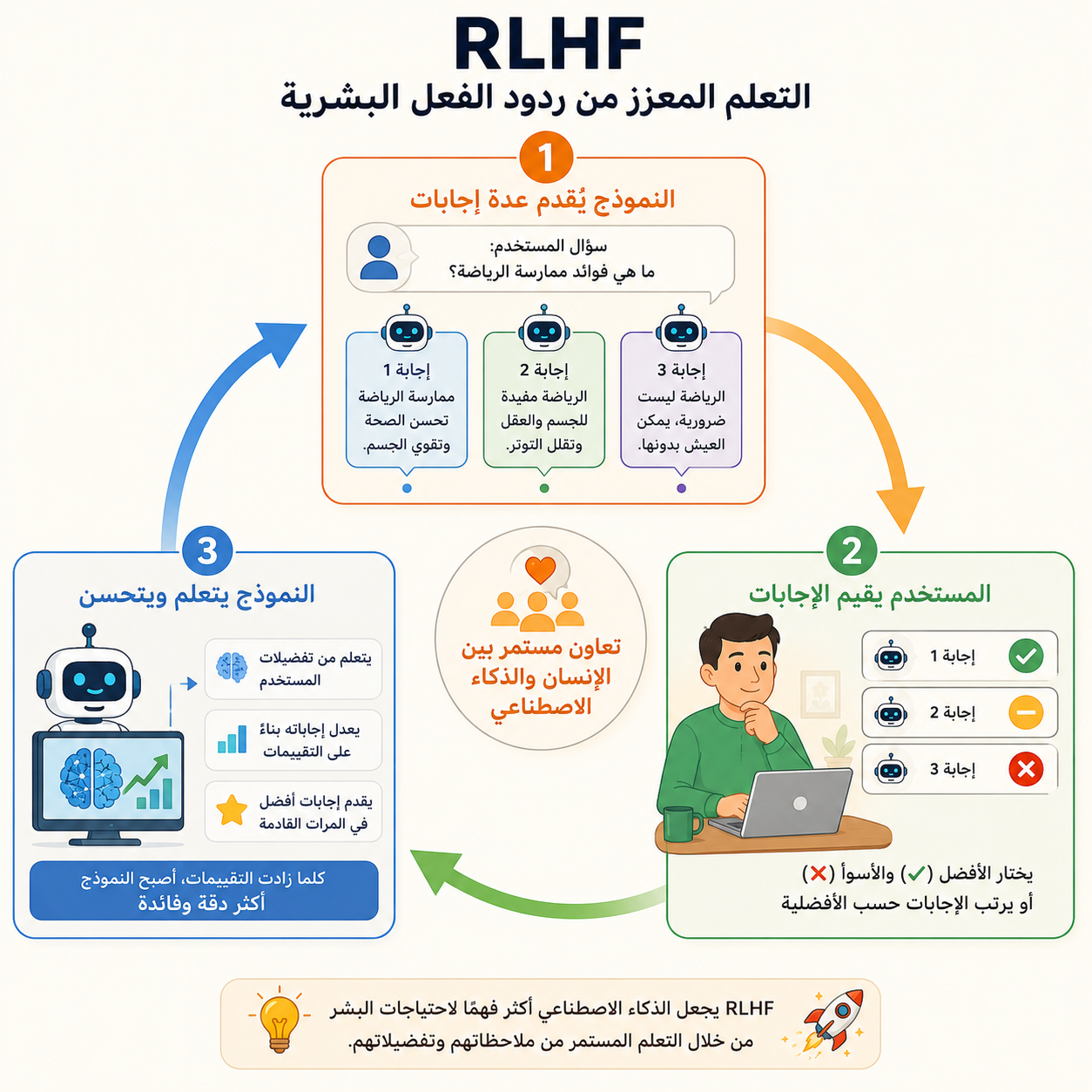
RLHF — حين يُعلّم الإنسان الآلة آداب الحوار
تستخدم شركات الذكاء الاصطناعي تقنية تُسمى التعلم المعزز من ردود الفعل البشرية (RLHF):
يُقدِّم النموذج إجابات متعددة لنفس السؤال. يُقيّم مقيّمون بشريون هذه الإجابات ويرتّبونها من الأفضل إلى الأسوأ. يتعلم النموذج من هذه التقييمات ليُفضّل الأسلوب الذي يُحبه البشر. تتكرر هذه الدورة حتى يصبح النموذج مفيداً وآمناً وطبيعياً في حواره.
هذا هو السر الذي جعل ChatGPT يتحدث بطريقة ودية ومفهومة وليس كآلة باردة تُدرج معلومات.
التحديات الكبرى في تدريب الذكاء الاصطناعي
تدريب نموذج لغوي كبير ليس مهمة بسيطة. إليك أبرز التحديات:
التكلفة الهائلة
تدريب نموذج مثل GPT-4 يُكلف عشرات الملايين من الدولارات في استهلاك الكهرباء والمعالجات وحدها. هذا هو السبب الذي يجعل هذا المجال حكراً على الشركات الكبرى مثل Google وMicrosoft وAnthropic وMeta.
الانحياز في البيانات
إذا كانت بيانات التدريب تحتوي على تحيزات بشرية — عنصرية، جنسية، ثقافية — سينقلها النموذج بصدق. هذه مشكلة حقيقية يعمل الباحثون على حلها باستمرار.
الهلوسة (Hallucination)
أحياناً يُنتج النموذج معلومات تبدو صحيحة لكنها خاطئة تماماً — “يخترع” أسماء كتب لم تُكتب، أو يستشهد بأبحاث غير موجودة. هذا يحدث لأن النموذج مُدرَّب على التنبؤ بما يبدو “محتملاً” لغوياً، لا على التحقق من صحة المعلومات.
الحد المعرفي (Knowledge Cutoff)
النموذج لا يعرف إلا ما تعلّمه حتى تاريخ انتهاء تدريبه. أحداث ما بعد ذلك التاريخ غائبة عنه تماماً — كإنسان استيقظ من غيبوبة ولا يعرف ما فات.

ملخص: دورة حياة التعلم في أربع خطوات
| الخطوة | ما يحدث | المثال |
|---|---|---|
| جمع البيانات | كميات ضخمة من النصوص والصور والأصوات | مئات المليارات من الكلمات من الإنترنت |
| التدريب | الشبكة تتنبأ وتُخطئ وتُصحح ملايين المرات | النموذج يتعلم أن “عاصمة مصر” تليها “القاهرة” |
| الضبط الدقيق | مقيّمون بشريون يُدرّبون النموذج على الحوار الطبيعي | ChatGPT يتعلم أن يكون مفيداً ولا يُضلل |
| الاستخدام | المستخدم يطرح سؤاله والنموذج يُجيب في ثوانٍ | أنت الآن تستخدم ناتج هذه الدورة كاملة |
خلاصة المقالة
يتعلم الذكاء الاصطناعي بطريقة مشابهة للإنسان لكن بحجم أضخم بكثير: يستقبل كميات هائلة من البيانات، يُخطئ في التنبؤ، يُصحح نفسه آلاف المرات حتى تنضج معرفته داخل ملايين الأوزان الرياضية. ثم تأتي مرحلة الضبط الدقيق التي يُعلّمه فيها بشر حقيقيون كيف يُجيب بطريقة مفيدة وإنسانية. ناتج هذه الدورة كلها هو النموذج الذي تتحدث معه اليوم.
المقالة القادمة
الآن بعد أن فهمت كيف يتعلم الذكاء الاصطناعي، حان الوقت لنتعرف على أنواعه المختلفة: الذكاء الضيق والذكاء العام والذكاء الخارق — ما الفرق بينها؟ وأيها موجود فعلاً وأيها لا يزال في دائرة الخيال العلمي؟ هذا ما ستكتشفه في المقالة الخامسة.
أنواع الذكاء الاصطناعي — الضيق والعام والخارق م/5
نهاية المقالة الرابعة — سلسلة الذكاء الاصطناعي من الصفر إلى الاحتراف efhm.online